The Science
Technology and society are changing faster than ever. That’s why employers, recruiters, and schools are all searching for people who are especially good at figuring out new ways of doing things, and drawing conclusions from new bodies of information — they are looking for people who are good at what we call “critical reasoning”. Unfortunately, the tools that these organizations currently use to search for such people are not designed to identify them. Those tools are instead designed to identify people who read quickly, or who have a good memory, or who know a lot about specific domains. REASZON™ is the first test that provides an accurate, unbiased assessment of a test-taker’s critical reasoning ability, and it does so at a small fraction of the cost of current assessments.
Decades of research in cognitive psychology (beginning with the Nobel-prize winning work of Kahnemann and Tversky in the late 70’s and early 80’s) have shown that human behavior is controlled by two distinct cognitive Systems. “System 1” arrives at verdicts quickly, effortlessly, and unreflectively, and it is well-adapted to help primates like us survive in an evolutionary environment that presents a narrow range of familiar, life-threatening challenges (e.g., how to escape or defeat dangerous predators): it is consequently inflexible and designed for caution rather than maximal accuracy. “System 2”, in contrast, arrives at verdicts slowly, deliberatively, and reflectively, and it is well-adapted to help us think through how to respond to novel challenges, and how to modify our responses as we gain new information: it is consequently flexible and designed to self-correct in order to achieve accuracy. As humans have built an environment that provides them with greater safety from life-threatening challenges, they face an increasing variety of novel challenges. Instead of having to find food sources or escape from predators, our challenge now is to find ways of adding value in an environment that is constantly changing in unpredictable ways. Because we are safe from the challenges that faced our evolutionary ancestors, System 1 is less important than ever. But because we are confronted with a rapidly changing set of novel challenges, System 2 is more important than ever. Consequently, many people today are interested in training their System 2 skills, and in evaluating the System 2 skills of people all over the world who are applying to study with them, or work for them. This interest in the assessment and improvement of System 2 has created today’s industry in training and testing critical reasoning skills, since critical reasoning is just the operation of System 2.
Stanovich, West, and Toplak have recently identified roughly two dozen parameters of critical reasoning ability and have also designed measures for ability along these various parameters. But the parameters that they identify are all manifestations of three fundamental abilities: (1) deductive reasoning, (2) pattern-recognition, and (3) distinguishing relevant from irrelevant information within a problem space. This reduction of parameters matters to the effort to build an accurate measure of critical reasoning skills, since it is much easier to construct a measure over a space with 3 dimensions than it is to construct a measure over a space with two dozen dimensions. REASZON™ is the first example of the former kind of measure. It assesses a test taker’s ability to reason deductively, recognize patterns, and distinguish information that’s relevant to answering a particular question from information that’s not relevant. And it is the only assessment to measure these abilities in a way that’s completely insensitive to those features of the test taker that vary independently of critical reasoning ability – for instance, the test taker’s reading ability, memory, or background knowledge.
(Stanovich, K. E., West, R. F., & Toplak, M. E. (2016). The rationality quotient: Toward a test of rational thinking. MIT Press.)
The REASZON™ assessment uses a Bayesian Computer Adaptive Testing algorithm to reduce the number of items needed to assess critical reasoning, and to better measure individual’s critical reasoning level. This algorithm requires calibration on a large sample of test takers. This calibration procedure determines the relation between item characteristics (e.g. complexity of the puzzle, number of decoy mirrors, etc.) and the distribution of critical reasoning. In traditional tests, which rely on a large number of premade items, this calibration determines the difficulty of each item. For the REASZON™ assessment, items are uniquely generated for each test taker, and rely on a set of item parameters that determine the form and difficulty of each item. The Bayesian nature of the calibration algorithm allows REASZON™ to generalize the item generation to any combination of the item parameters.
Once the REASZON™ test is calibrated, the computer adaptive nature of the test allows for fast measurement of an individual’s critical reasoning, as each item is generated at the individual’s expected critical reasoning score. This lets the assessment quickly attain an optimal difficulty for each individual, and refine each individual’s score by slightly varying the difficulty of the generated items.
The current calibration sample is an internationally representative sample of 2639 individuals who were enrolled in Dr. Neta’s critical reasoning Coursera MOOC (“Think Again: How to Reason and Argue”). This sample was approximately 55% male, with an age range between 17 and 77 (average age of 40). Approximately 51% of the calibration sample had completed a bachelor’s degree or above. Using this sample, the REASZON™ was calibrated and the resulting population critical reasoning distribution was normalized to a standard normal distribution.
The standardization using the calibration sample allows for the comparison of individual scores to the population curve, which leads to the production of percentile scores (e.g. Test taker scored in the 70% percentile, suggesting that their critical reasoning was better than 70% of the population.)
Standardization allows for the calculation of other population level curves, which allows REASZON™ to report comparisons against a variety of sub-populations (e.g. test taker scored in the 70% percentile of computer science majors, and in the 80% percentile overall.)
Finally, for interpretability overall percentile scores are converted into a numerical score that ranges from 700-1300, with 1000 representing the 50% percentile.
In addition to calibration, REASZON™ was compared against commonly used measure of critical reasoning, ETS HEighten , as well as several academic outcomes of interest.
In our first validation study, REASZON™ was administered alongside of ETS HEighten to 182 business school students. GPA, SAT Verbal and SAT Math scores were collected, along with demographic information such as race, gender and age.
General linear models were fit predicting GPA, SAT Verbal and SAT Math scores by REASZON™ score and demographics, as well as ETS HEighten scores and demographics. Interactions between REASZON™ score and demographics were examined, and none were found to be significant. This suggests that REASZON™ is unbiased by demographics in terms of its predictive ability. Furthermore, the total predictive ability in the form of R2 , a scale-free indicator of model fit, was examined for both the REASZON™ model and HEighten model. For GPA, the REASZON™ model had an R2 of .172, while the HEighten model an R2 of .1767, indicating that HEighten explained no more than .5% more variance in GPA than REASZON™, a trivial difference. For SAT Math, REASZON™ had an R2 of .4127, while HEighten had an R2; of .4175, again suggesting that HEighten explained no more than .5% more variance in SAT-Math scores. Finally, for SAT-Verbal, RE ASZON™ had an R2 of .2832, while HEighten had an R2 of .5831, which suggests that HEighten explains 29.9% more variance in SAT-Verbal scores.
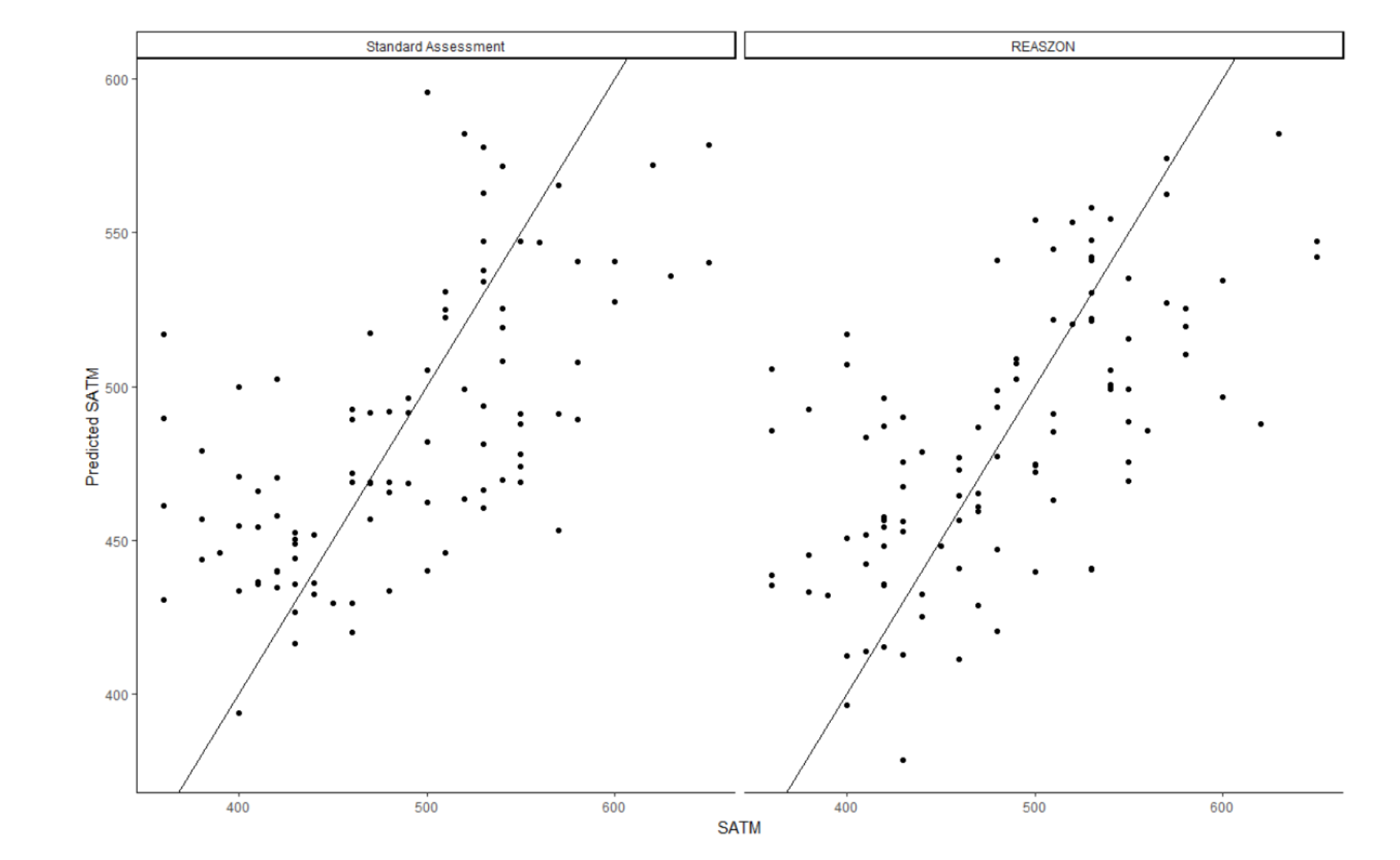
This set of results suggest that REASZON™ performs comparably to HEighten with regard to GPA and SAT-Math, while it underperforms with regard to SAT-Verbal. This result is not unexpected, as ETS HEighten has a significant verbal comprehension component, as it relies on complex vignettes. REASZON™ does not rely on complex vignettes, and instead uses a limited vocabulary (if, then, else), and a simple set of concepts. This difference in test construction is likely the reason for the difference in performance on the SAT-Verbal. But it is precisely this same difference that allows REASZON™ to measure critical reasoning skill in a way that avoids bias introduced by differences in reading comprehension and culturally-specific background knowledge.